
- HDFS works on cluster, which means you don’t have to think about filling this or that server anymore.
- HDFS scales horizontally.
- HDFS works great with big big files.
- HDFS splits the big files in chunks, so storing a 10+TB database is easy.
- HDFS is object storage, so you can easily run mysqldump | xbstream -c | hdfs — to store large MySQL databases.
- Because you’re running of a bunch of servers at the same time, you solve the I/O problems.
- HDFS manages replication. No more lost backups because a single server crashes.
- HDFS is perfect for JBOD. No more RAID which costs money and I/Os.
- You can use small machines with just a bunch of 4 to 6TB spinning disks and let the magic happen.
Once again there are a few cons:
- HDFS is not so good at managing a gazillion small files.
- Unlike ZFS / rsnapshot, HDFS does not handle file deduplication natively (but space is cheap)
- Complexity: you need a full HDFS cluster with name nodes, journal nodes etc…
- The HDFS client requires the whole Java stack which you don’t want to install everywhere.
Implementation
We started to work on a quick and dirty POC to provide a HDFS backed backup system.
- It uses a lightweight HDFS client written in Go.
- It manages backup rotation with variable retention (hourly / daily / weekly / monthly).
- It runs parallel backups.
We started to test it on a small HDFS cluster:
- 2 small 20$/month servers.
- 4 * 4TB JBOD spinning disks.
For directories full of small files like /etc/, the throughput is about 30% slower than a simple rsync.
For large files, the throughput is 20% faster than rsync because we’re limited by the network.
The good point: restoring a file is not about looking for a needle in a haystack anymore. All my prerequisites are satisfied.
The bad point: complexity. Building even a small HDFS cluster is a bit overkill for your home backup. But for a professional use, it works like a charm.
HDFS elaborates to be Hadoop Distributed File System. This is a file system that’s used to operate upon very large data sets which the present day’s technology is producing on immense proportions. The size of file units stored in HDFS can range from Gigabytes to Terabytes, and sometimes even larger.
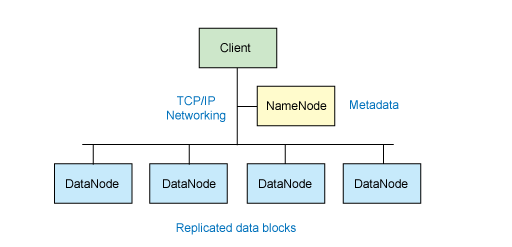
NameNodes:
NameNode is the repository of mappings to various DataNodes, meaning that it contains the information regarding the mappings between different files, their locations and their corresponding DataNodes that are branched under the NameNode.
DataNodes:
DataNodes are the actual areas where the files are stored in the file system. There will be numerous DataNodes linked to one NameNode.
They send reports regarding their files to the NameNode for every 10 seconds. This report is called Heartbeat. It proves that a particular DataNode that has successfully reported its Heartbeat to the NameNode, is safe and secure and is alive and active.
So, when a beat is skipped by a DataNode the NameNode instantly recognizes the in-activeness in that DataNode; and when this in-activeness continues for 10 minutes, the DataNode is declared dead and then on no IO will be sent to that node, and the data present in it is replicated to another DataNode and these new changes are updated into the NameNode’s mappings.
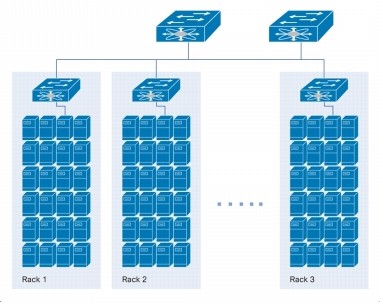
Racks and Replications:
Files are maintained as a series of blocks and the size of all the blocks are same except for the last block. And, many such blocks are put into Racks.
Replication is performed into the racks and these replication decisions are taken by the NameNode.
Replication of files is placed into different unique racks to ensure against the possibility of data loss, just in case a complete rack failure should occur. And to write these replications into different racks it would cost more writing; but then, in the aftermath of rack failure, wouldn’t we regret not writing data to other racks than losing all of it.
EditLog:
There will be new files and directories created in the file system. As these changes occur in the metadata, they’re all recorded in a log called, EditLog and later updated in the NameNode.
HDFS is the most advanced distributed file system and is undergoing a quick transformation and coming of age with the advancement in the technologies. This is going to be a huge requirement for the BigData generation that’s shaping up in front of our very eyes.
Did you find this article useful? Let us know by leaving a comment below, or join us on Twitter and Facebook.


