Nowadays Serverless is one of the hottest buzzwords in the technology world. many experts believe that serverless computing is the future, as mobile and Internet of Things applications continue to fuel demands for serverless architecture, coupled with the growing need to integrate cloud applications with mobile and desktop apps.
Traditionally, servers are based around a client-server architecture. This means that a server is hosted on a computer with the purpose of delivering the content to the client and accessing the database to retrieve information. Serverless architectures seek to improve upon the traditional client-server structure by reducing processing load and allowing efficient scaling.
Serverless Computing is the next evolution of IaaS (Infrastructure as a Service). Developers are build their applications by writing a function that responds to a given event. Once application are deployed, serverless infrastructure can execute functions automatically in response to events. Typical provisioning activities expected of a developers such as hardware provisioning, configuration, capacity reservation, release etc. Auto scaling and load balancing are automatically triggered as necessary based on the load. The lifecycle of the functions is very short and is the time to execute a single request.
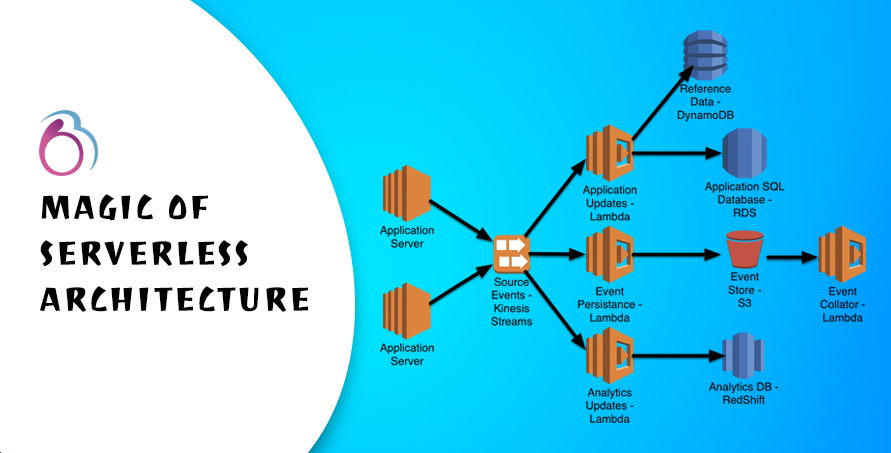
Despite the name “serverless” there are still server involved in this process, but it works a little differently. For this example, we will use AWS infrastructure. When the users requests a serverless app, instead of going straight to a server it first stops by AWS API Gateway. In this scenario, our domain name would be pointed at the API Gateway instead of at an individual server. Once the API gateway get the request, it will trigger the Lambda function. This is where the magic begins. As part of the triggering of Lambda function, a temporary server is created. Once the server is created, it will handle the request, and then send a response back to API gateway. As part of the finishing of the Lambda function, the server will then be torn down, and API Gateway will send the response back to the users.
There are some advantages that this setup provides:-
- We don’t have to worry about scaling.
When a new request comes in a server is created that will handle that request. In essence 600 requests = 600 microservers. If you have a burst of traffic or there is a lull, you’re fine. No more need setting up and tearing down servers or writing complicated scripts to handle the workload.
- No server maintenance is required.
In serverless set up we don’t need to worry about the staying up to date with Operating system or security patches. We don’t have to worry about what type of server or virtual machine we should use.
- You can focus on building.
Perhaps the most compelling reason to switch to a serverless architecture is that we can spend more of our time in developing. The reason we build website and services is to provide the value to our customer. Fewer time focusing on infrastructure mean more time for creating value for our customers.
There are some demerit in Serverless computing, it should not be seen as a magic bullet to solve all computing problems. The scalability and financial incentives provided by this platform in terms of per-request pricing provide a solid use case like bursty, highly elastic workloads. Also this platform is suited for an agile approach to software engineering involving quick deployment of small feature slices, customer feedback and further development loops. Hence, it will be a good fit for solutions implementing Customer Experience, Digital transactions and API traffic which exhibit these patterns. The transition journey of the serverless computing to a mature technology will be highly exciting.


